This is the second-instalment of "Big Data, Predictive Analytics and Reliability – Moving Beyond Better Maintenance." Find part I here.
The four pillars of reliability
So how do these advances in data impact reliability. To better understand, let’s look at the four key pillars of reliability – Reliability in Design, Operate for Reliability, Preventive Maintenance Strategies, and Defect Elimination.
Reliability in Design
IIoT and big data already have a significant impact on design. In the past, equipment manufacturers sold equipment, and their most reliable sources of in-field performance data were warranty claims, spare part orders and customer complaints. Today, many manufacturers are fed real-time or near real-time data about their equipment and have much better visibility of machine performance, informing modifications to existing equipment and design enhancements for future equipment.
This extends from the humble motor vehicle with its engine management system for recording data that is downloaded during servicing; to large mining equipment beaming telemetry data back to the manufacturer via satellite; and to aircrafts all over the planet sending live engine telemetry to the manufacturer. Similarly, within manufacturing and processing facilities, these same technologies can be used to better understand plant performance and improve reliability.
This improvement can be related to individual machine reliability, which we will cover in Defect Elimination. More importantly, by considering the manufacturing or processing facility as a system, we can focus on maximising system reliability by making real time decisions that match production rates to productive capacity, capitalise on redundancies, alternate pathways, and load share to distribute wear and tear to optimise overall system performance.
Operate for Reliability
While it is widely recognised that choosing the right equipment in the first place has the most significant impact on reliability, the next most significant impact is the way that the equipment is operated and ensuring that it is not operated outside of its intended operating envelope. Again, taking the humble motor vehicle, we take for granted sensors that alert the driver to all manner of issues from low oil pressures or high engine temperature, to deflating tyres and failing alternators.
In a similar way, IIoT allows us to better inform human operators when they are about to stray beyond the equipment envelope. Alarms and alerts are a simple form of this, but this same data can be used to inform training needs to produce better operators rather than detecting events as they occur. Take for instance mining haul trucks where gear change events, brake application, speed, load, and engine RPM can be monitored from afar to observe operator behaviours that need to be corrected. Then, scorecards and training programs are developed accordingly.
The move to an automated world will demand even more of this technology. In the past, as we drove our motor vehicle to work, a squeal from the rear of the car as we turned a corner, combined with an odd ‘feel’ alerted us to a flat tire. Today, we are just as likely to see a warning light that we have low tire pressure. But fast forward to the world of an automated vehicle on its way to collect a passenger – it doesn’t have the luxury of a driver to determine the most appropriate intervention. It will rely on a prescriptive algorithm to determine the most appropriate action.
Preventive Maintenance Strategies
The advent of new sensor technologies and the decreasing cost of existing technologies provides new methods of monitoring asset condition, detecting the onset of failure, and fine-tuning the timing and type of intervention.
Traditional FMECA and PM optimisation approaches have relied on work order data to understand parameters such as mean time between failure. Reliability analysts are often challenged by incomplete data, such as breakdown events that do not result in a work order, events that are recorded against a parent equipment and not counted in the component failure rate. Sensor data collected, stored and available for analysis provides a much more consistent and reliable set of data to support this analysis.
Defect Elimination
The final pillar is the Defect Elimination process – proactively identifying sources of loss, prioritising these losses for investigation and resolution, conducting a root cause analysis to identify actions to eliminate the loss, tracking actions, and confirming that the actions actually eliminated the defect.
In the past, loss and delay accounting data has typically been used to identify improvement targets. While acute (one-off, major) losses typically stand out and are easy to identify, chronic (frequent but less severe) losses are sometimes harder to discern – different operators may code the same failure in different ways, etc. Further, while for acute failures the cost of lost production typically outweighs maintenance costs, for chronic failures, maintenance costs can start to stack up and even outweigh production losses.
Using sensor data to better inform the delay and loss accounting system leads to more accurate and consistent capture of delay and loss events, while the ability to blend this data with maintenance cost data using big data tools provides the ability to pinpoint major sources of loss.
This same data can be used to support the root cause analysis process. In some cases, the cause of failure may be evident, but in others, the availability of persistent high-resolution data may offer previously unavailable information on the cause of the failure.
The final step in the Defect Elimination process is to ensure the defect has actually been resolved. Again, the availability of persistent high-resolution data means that assessing performance before and after the resolution has been implemented is readily measurable.
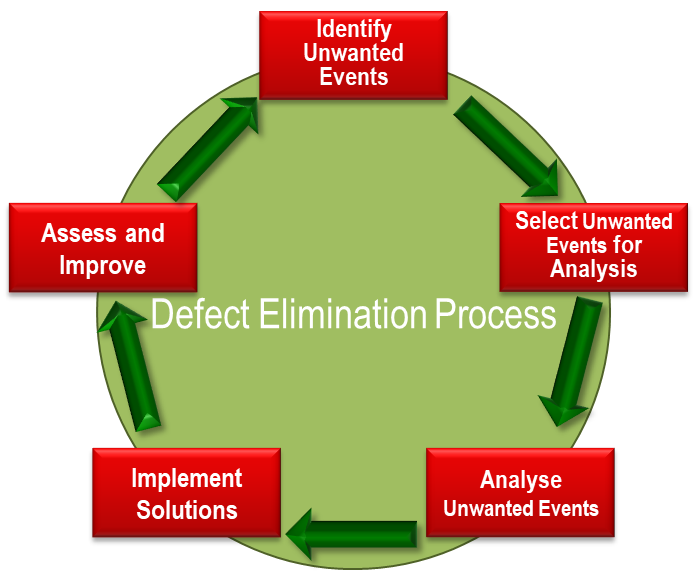
Figure 2 – Defect Elimination Process
Conclusion
In this article we have considered how the abundance of accessible and consistent data, combined with applications to support visualisation, modelling, analysis and machine learning, can be used to support the four key pillars of modern reliability engineering, namely:
Reliability by Design, Operate for Reliability, Maintenance Tactics Optimization, and Defect Elimination.
The question really is when should it be used. As noted in the introduction, many businesses have invested significant amounts to build expensive ‘data lakes’ in the hope that they will one day be useful to the business. That is one approach, but we would suggest a more pragmatic approach is to invest in understanding these new technologies to determine how they can help to solve real business problems rather than investing in the latest shiny thing for the sake of it.
We encourage you to think about how these emerging technologies might support your business and how you might go about developing pragmatic, cost-effective and implementable solutions to maximise return on investment.