This is the second installment of Robert Martin's article, "Using Detection Technology to Enhance a Predictive Maintenance Program." Find Part I online here.
Strategies for implementing Detection Technology
Determining which assets are candidates for implementing detection technology should be done in a logical and systematic way. To do this we have to first determine what kind of failure profile each particular type of asset has. The failure curve below denotes two specific times in a machines life. The first would be the point shown as P. This is the point where an impending failure is first detectable. The second point is F. This is the point where a functional failure begins. This does not necessarily mean that the machine has stopped running. To me it means that anyone could walk near this machine and know that something is wrong. Think smells and sounds that don’t belong.
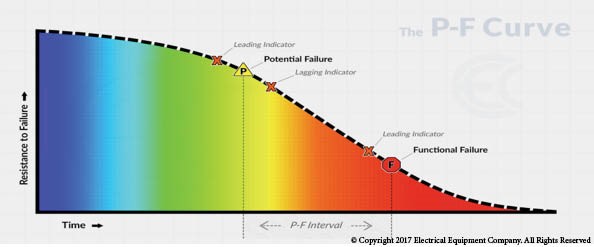
Not all machines fail in the same way
Note that time is not clearly defined on the graph. What this implies is that the time interval between the potential failure and functional failure varies by machine. This is where you need to ask yourself how quickly this machine can make the change from healthy to unhealthy. If the answer is a matter of months, detection technology may be a good fit. If it’s a matter of hours or minutes, then your route based program probably isn’t going to help anyhow and detection technology is probably again a good alternative. Of course this is not the only criteria involved in this choice. Machine criticality plays a part as well.
Not all machines are critical
If you are involved with reliability at you plant you know that the criticality of your assets, regarding safety and plant performance, is important to determine. Just because a particular asset is troublesome to repair when it fails, does not make it a critical asset, although many times a sensor is slapped on it so that it never fails like that again!! An important point to remember is that a sensor will not, on its own, prevent a machine from failing! People need to get involved and decisions need to be made. True critical assets are assets that can hurt people or inhibit production for an unacceptable period of time if they fail. Assets that have redundancy are, most times, not as critical as those that are bottlenecks to production. This is particularly the case when the repair involves waiting for special parts from a faraway land that takes months to be delivered.
Not all machines are failure prone
I was once involved with a water department in a big city. Their maintenance staff was asked what their most critical assets were. Without hesitation they mentioned that the pumps were the most critical asset that they had. They were then asked whether they ever failed. To that they answered that they were very well built and never failed. Regardless of their perceived criticality, if the asset doesn’t fail very often, it probably doesn’t need anything more than simple route data collection, just in case. Nothing is perfect.
Easy Candidates for Detection Technology:
Not all machines are easy to collect data on – Nasty but necessary
If you want an easy place to start a detection technology implementation where you won’t get much pushback, find machines that are located in the worst places. If it’s mounted on top of an oven or deep in a grimy pit, a machine will not be popular with your vibration crew. Having a way to monitor its condition remotely will be more easily accepted by them. The only time that they have to visit the asset is when a problem is detected.
Non-Critical and reliable
The first place to consider detection technology is the most obvious choice, machines that have long failure profiles that are not critical and don’t fail very often. If you think about it, every plant has these. Sometimes they are air handlers or slow speed gearboxes or even hydraulic power units. They need to be monitored, but seldom cause anyone any trouble. In the case of air handlers, detection technology can be used to determine when it’s time to clean the fan blades, for example. The payoff of using detection technology with these assets is that they can be eliminated from monthly routes allowing your program to spend more time on more critical assets.
Critical yet reliable
Another place for detection technology are assets that absolutely have to be monitored but seldom fail. These bottleneck machines are important enough that routes are collected on them month after month without much change in the data. It would be unacceptable to stop monitoring them, but the routes could be best run somewhere else. Detection technology not only fills the role of monitoring these valuable assets, but actually gives you more warning of impending trouble. Using a 4-20ma sensor with both velocity and true peak being tracked and trended provides an endless stream of data that can not only detect problems, but also show when deviations from normal operation occur. When an issue is detected, it’s time to run the vibration route points and see what’s up.
Critical with a quick failure profile
These are assets that have a quick failure profile that is seldom, if ever, predicted. These are the nightmare machines that keep us up at night. Years ago, I was working with one of the auto manufacturers who had environmental chambers that used a unique fan design. Even though data was collected on these on a monthly schedule and showed no problems, these units would self-destruct for no apparent reason. And when I say self-destruct I mean that aluminum parts would melt away and the fan rotor would detach from the drive shaft. When the dust cleared, the entire machine would have to be replaced. For this reason, getting people to climb into the enclosure to collect route data got more difficult as time and failures went by. Also, there was a lot of frustration because of the inability to detect impending disaster.
A good monitoring alternative for this type of asset would be a sophisticated detection technology that has both velocity and high frequency detection outputs that are continuously sent to the controls logic for both trending and alarming. By doing so, it would be possible to not only detect failures when they were about to occur, it would also be possible to monitor these events in relation to other machine conditions that might lead to clues to why the failure occurs in the first place.
Non-critical and reliable
These are assets that would be troublesome if they failed, but are easily and economically replaced or repaired without causing any significant downtime or safety risks. Redundant pump systems or small conveyor drive units are good examples of this type of asset. Using a detection technology on these assets could eliminate them from vibration routes while at the same time providing better protection from unplanned failures. A secondary benefit would be the ability to monitor start and stops on these assets by monitoring running vibration in relation to shutdown vibration.
All things in moderation
It is important to understand that detection technology is only an option and not a cure all. There are assets that require a comprehensive on-line monitoring system that updates continuously while there are others that can be successfully monitored with detection technology. In between are those assets where a route based approach makes absolute sense.
It is also important to understand how your plant operates and how its corporate culture reacts to change when implementing detection technology. Having a history of how assets have failed in the past and tapping into that history can be invaluable in determining which assets are good candidates for detection technology. Sometimes this record is written down, but other times it is found in the oral story telling tradition. Any good vibration analyst knows to ask lots of questions when a machine failure is chronic. Referring to the “old hands” at the plant can yield great insights into what happened when and why. This information can help you determine where detection technology can have the most impact.
Finally, it is important to understand although detection technology has been around in one form or another for several years now, the need to implement it in active predictive maintenance programs is a recent development. Thankfully, the technology has not remained stagnant and is continuing to be developed as demand increases.
In a perfect world we would have the staff and expertise to run the comprehensive predictive maintenance programs that I experienced in the 90s and early 2000s. Unfortunately, the shortage of trained staff coupled with increased demand for greater and greater plant reliability and throughput have created a situation where we could fall short. The good news is that detection technology can sometimes fill this capability gap in a way that provides benefits for all concerned by helping to achieve these goals with the staff that we have.